Abstract
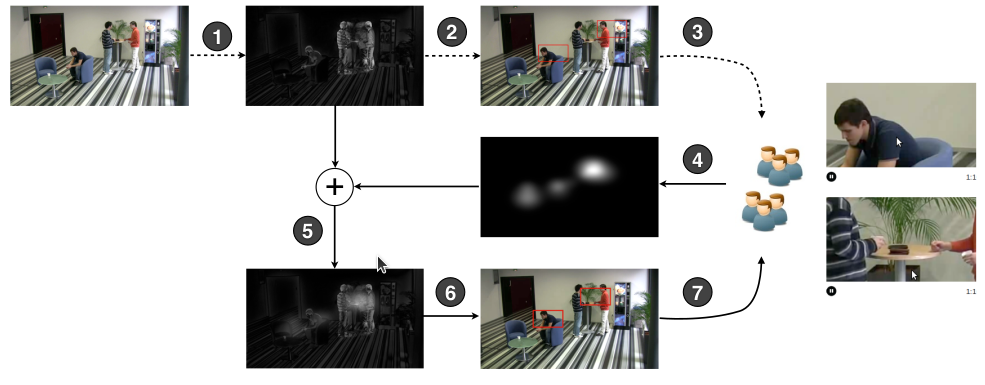
This paper introduces a new paradigm for interacting with zoomable video. Our interaction technique reduces the number of zooms and pans required by providing recommended viewports to the users, and replaces multiple zoom and pan actions with a simple click on the recommended viewport. The usefulness of our technique is visible in the quality of the recommended viewport, which needs to match the user intention, track movement in the scene, and properly frame the scene in the video. To this end, we propose a hybrid method where content analysis is complimented by the implicit feedback of a community of users in order to recommend viewports. We first compute preliminary sets of recommended viewports by analyzing the content of the video. These viewports allow tracking of moving objects in the scene, and are framed without violating basic aesthetic rules. To improve the relevance of the recommended viewports, we collect viewing statistics as users view a video, and use the viewports they select to reinforce the importance of certain recommendations and penalize others. New recommendations that are not previously recognized by content analysis may also emerge. The resulting recommended viewports converge towards the regions in the video that are relevant to users. A user study involving 70 participants shows that an user interface incorporating with our paradigm leads to more number